📍 名前難読化の逆変換
🗣 研究概要
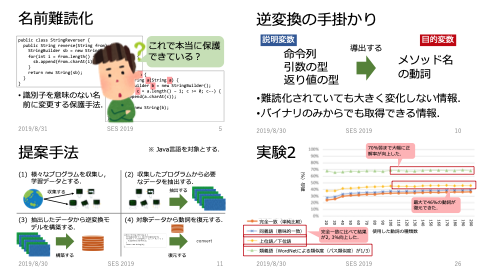
ソフトウェア内部に含まれる秘密情報を保護するために,ソフトウェア保護技術が広く用いられている. その一つに,プログラム中の秘密情報を秘匿するために,プログラムを読みにくく変更する難読化手法がある. プログラム中のどの特徴に着目して,読みにくく変更するかにより,異なる手法が提案されている. その中でも特に広く使われている難読化手法が名前難読化である. プログラム中に含まれる識別子名を意味のない名前に変更することで,可読性を下げる手法である. しかし,名前難読化の耐タンパ化性能はこれまでに議論されたことはない. もし,識別子名の復元が可能であれば,名前難読化手法は脆弱な手法であり,そのことが知られないまま使い続けられていることになる. そこで,名前難読化の耐タンパ化性能の評価のために,逆変換を試みる.特にメソッド名に着目しての復元を試みる. 復元のために,難読化手法では変更されにくいメソッドの命令列,そして,メソッド引数の型と戻り値の型に着目する. 大量のプログラムを用意し,これらのデータを機械学習にかけ,復元モデルを構築する. そして,復元したいメソッドをモデルに適用し,メソッド名の復元を試みる.
Maven Central RepositoryのJavaのデータからモデルを構築し,モデル構築に含まれなかったJavaプログラムを対象に復元を行った. その結果,全体の 31.62%の動詞の復元に成功した. また,動詞の意味的な類似度に基づいた評価では,同義語では 33.94%,上位語の関係では40.07%のメソッド名の動詞を復元できた.
(磯部 陽介, 玉田 春昭, “ランダムフォレストを用いた名前難読化の耐タンパ化性能の評価”, 情報処理学会論文誌, Vol. 60, No. 4, pp. 1063–1074, April, 2019 概要)